RAG Book Recommendation Chatbot
Retrieval-augmented generation (RAG) is one of the most useful and popular applications of large language models. LLMs often hallucinate, but RAG, along with prompt engineering, is a powerful way to improve the accuracy of an LLM’s responses.
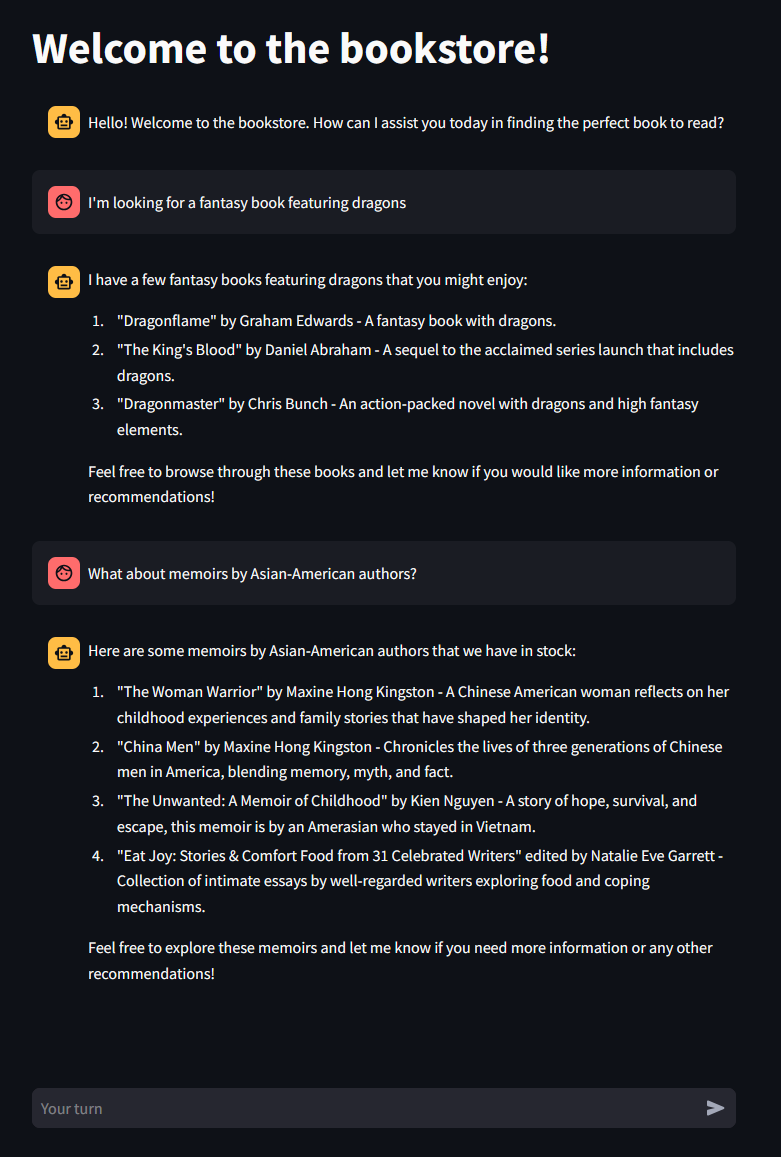
I like to read books, and I found a books dataset scraped from Goodreads. Using that dataset, I created a very simple RAG chatbot that recommends books to users.
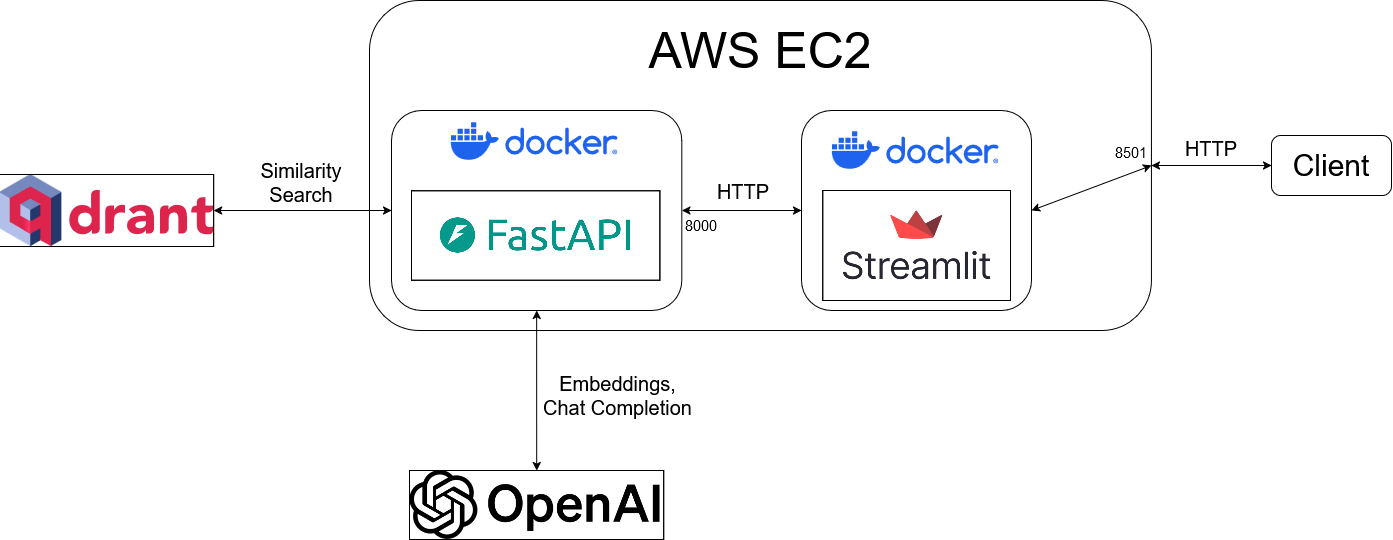
The backend is developed with FastAPI and the frontend with Streamlit. Backend and frontend are deployed to separate containers and communicate via a virtual Docker network - the backend is only accessible to the frontend, and the frontend is exposed via an EC2 instance.
I used OpenAI’s text-embedding-ada-002 model to embed the book descriptions and indexed the embeddings and relevant metadata into Qdrant. The frontend posts user messages to the backend, and the backend embeds the message and retrieves the top 5 most similar books from Qdrant. The book titles, authors, descriptions, and genres are passed to OpenAI’s chat completion API, and the chat completion is passed back to the frontend and added to the conversation history maintained in both backend and frontend.
Tools, libraries, and APIs:
- FastAPI (backend)
- Streamlit (frontend)
- OpenAI (text embedding and chat completion)
- Qdrant (vector database and similarity search)
- Docker and Docker Compose (containerization and networking)
- AWS ECR, AWS EC2 (deployment)
UI:
Architecture:
Project directory structure:
.
├── backend
│ ├── __init__.py
│ ├── dependencies.py # Dependency functions to inject BookRetriever into /chat/ operation function
│ ├── main.py # Create one instance of BookRetriever to be shared among all users
│ ├── models
│ │ ├── __init__.py
│ │ ├── assistant.py # BookAssistant class definition
│ │ └── retriever.py # BookRetriever class definition
│ └── routers
│ ├── __init__.py
│ └── chat.py # /chat/ endpoint
└── frontend
└── app.py # Streamlit application for UI
Future work:
- Machine learning improvements
- Add intent classifier to classify the user query into requiring retrieval (e.g. “Recommend me a fantasy book”) or not requiring retrieval (e.g. “How are you doing?”)
- Add NER classifier to extract key information from the user query (e.g. author, rating, popularity, etc.) to use for metadata filtering during retrieval
- Add NLP summarizer to summarize long book descriptions before passing to chat completion model (currently, descriptions are arbitrarily truncated to 150 characters)
- MLOps improvements
- Implement unit tests
- Implement CI with GitHub Actions
- Redesign the frontend using an asynchronous framework to better support concurrent users
Backend
The backend is developed with FastAPI and provides a single endpoint, /chat/, to handle user messages.
Key components:
- Models
- Embedding: OpenAI
text-embedding-ada-002 - Chat completion: OpenAI
gpt-3.5-turbo
- Embedding: OpenAI
- Vector database: Qdrant
- Endpoint
- Path:
/chat/ - Request: accepts a JSON object
{ "userid": "exampleuserid", "message": "I'm looking for a fantasy book featuring dragons." } - Response: returns a JSON object
{ "response": "Based on your preference for a fantasy book featuring dragons, here are some recommendations from our bookstore:\n\n1. \"Dragonflame\" by Graham Edwards - This book falls under the Fantasy genre and features dragons. Unfortunately, there is no description available for this book at the moment.\n\n2. \"Pete's Dragon (Little Golden Book)\" by Walt Disney Company - This children's book is a Fantasy story that includes dragons. It combines elements of humor, animals, and fantasy for an enjoyable read.\n\n3. \"Free Fall\" by David Wiesner - While this is a Picture Book, it also includes dragons in the story. It follows a young boy's dream about dragons, castles, and a faraway land, offering an adventurous and imaginative read.\n\n4. \"Dragonmaster\" by Chris Bunch - A fantasy novel that features dragons, war, and magic. It promises action-packed adventure in a fantastical setting.\n\n5. \"The King's Blood\" by Daniel Abraham - This book is an Epic Fantasy sequel that includes dragons in its narrative. It is filled with war, adventure, and a rich fantasy world for readers to immerse themselves in.\n\nFeel free to explore these options and see which one intrigues you the most for your next fantasy read! Let me know if you need more information on any of these books." } - Path operation
- Embed
message - Retrieve similarity search results from vector database
- Concatenate
messagewith search results and pass to chat completion model, then return the generated response
- Embed
- Classes
BookRetriever- Asynchronously embeds user queries and retrieves similarity search results
- A single
BookRetrieverinstance is created in the FastAPIlifespancontext and shared among all users to reduce overhead
BookAssistant- Asynchronously generates responses, given
messageand the search results, and maintains conversation history - Each user gets their own
BookAssistantinstance, stored by user ID in a dictionary in memory, alongside a mutex lock to prevent race conditions
- Asynchronously generates responses, given
- Path:
Frontend
The frontend is developed with Streamlit. The frontend is responsible for the UI, for generating unique user IDs, and for sending HTTP POST requests to the backend.
Containerization and networking
This project uses separate Docker containers for the backend and frontend.
Architecture
- Backend container
- Exposes port 8000
- Accessible only to the frontend via a virtual Docker network named
app-network
- Frontend container
- Exposes port 8501, which is forwarded to port 8501 on the host machine
- Provides the user interface accessible in a web browser
Refer to ./compose.yaml for the Docker Compose configuration.
Setup instructions
- Create a file called
./backend/.envwith these environmental variables defined:QDRANT_URL=<my-qdrant-cluster-url> QDRANT_API_KEY=<my-qdrant-api-key> OPENAI_API_KEY=<my-openai-api-key> - Install Docker and Docker Compose on your machine
- In your terminal, navigate to the directory containing
compose.yamland executedocker compose up. This command builds and starts both containers. - Open your web browser and navigate to
http://localhost:8501to access the application UI
Dataset and embedding
This dataset contains scraped books data from Goodreads, including fields like description, genre, number of ratings, rating on a 5-star system, etc.
For each book, I concatenated the book description with the genres list, fed them into the text embedding model, and then stored the embeddings, along with metadata, into the vector database.